Antes de começarmos...
Estou partindo do princípio que você já sabe o que é um índice e que ao menos conhece a sintaxe de criação, caso contrário, clique aqui.
A verdade sobre os índices:
Imagine uma rotina que realize a seguinte consulta:
SELECTAo exibir o Execution Plan dessa query, poderemos ver o seguinte:
d.Name, e.Title, e.ContactID, e.Gender
FROM
HumanResources.Department d
INNER JOIN
HumanResources.EmployeeDepartmentHistory edh ON edh.DepartmentID = d.DepartmentID
INNER JOIN
HumanResources.Employee e ON e.EmployeeID = edh.EmployeeID
WHERE
edh.EndDate is null

Analisando a ação de maior custo, Clustered Index Scan na tabela Eployee, podemos ver que este está utilizando um índice primário na chave primária da tabela (EmployeeID). Essa operação naturalmente irá gerá um custo maior, pois em nosso SELECT estamos solicitando mais dados do que o índice está trazendo, forçando o SQL Server a procurar os dados utilizando como base apenas a chave primária da tabela, como podemos ver ao exibir os detalhes da ação deixando o cursor do mouse em cima do ícone da mesma:

Sendo assim, vamos criar um índice para os dados solicitados na query acima:
CREATE INDEX IX_Employee_1 ON HumanResources.Employee(Title, ContactID, Gender)Agora, vejamos o resultado obtido:
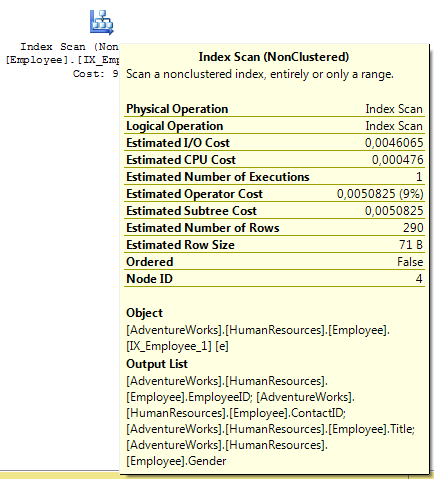
Conseguimos reduzir o custo total de 0,0080454 (14%) para 0,0050825 (9%), muito bom...será mesmo? Temos que tomar um cuidado extremo com a criação de índices em nossas tabelas. Uma tabela com poucos índices poderá causar-lhe muitos problemas, pois os dados não estarão ordenados, causando assim uma lentidão nas consultas a base de dados e consecutivamente em todas as aplicações que dela dependem. Em contrapartida, uma base de dados com muitos índices também poderá causar-lhe muitos problemas, já que quanto mais índices em uma tabela, maior será o custo para inserção, impactando na aplicação que depende dessa tabela . Mas então como encontrar o equilíbrio?
Antes de tentarmos encontrar o equilíbrio dos índices, vamos entender um pouco mais sobre os tipos de índices e o que é Fill Factor.
Índices primários e secundários:
Existem dois tipos de índices: os índices primários (também conhecido com Clustered Índex) e os índices secundários (NonClustered Índex). A diferença entre os dois tipos de índices não está relacionado com a sua importância, mas sim onde os arquivos que dos índices ficarão armazenados e o que eles guardarão.
Os índices primários são mais robustos que os secundários, pois eles guardam a posição física dos dados, são automaticamente ordenados e são ficam no mesmo grupo de arquivos que as suas tabelas. Segue abaixo um diagrama mostrando como funcionam os índices primários:

Explicando o diagrama, na parte superior temos os nós base, onde fica o ponto de partida para o SQL Server percorrer o índice. Mais abaixo temos os nós intermediários e no fim as folhas (é assim chamado devido a semelhança com uma arvore e suas folhas). As folhas contém os dados propriamente dito, ou seja, onde ficam armazenados os endereços físico dos dados que queremos obter. Por exemplo, desejo obter os dados do cliente que tem o ID 444, logo vou atrás do endereço físico desses dados:

Primeiro o SQL Server verifica: 444 é menor ou maior que 500? É menor, então vou para o nó da esquerda e repete a verificação: 444 é menor ou maior que 250? É maior, então vou para a folha da direita. Agora o SQL Server reduziu a sua busca de 1000 registros para 250, ou seja, uma redução de 75% de I/O de Disco. Por isso é importante toda tabela ter um índice primário (o SQL Server permite apenas um Índice Primário por tabela) em um campo com unicidade garantida, de preferência por uma Constraint.
Os índices secundários por sua vez, não são tão robustos quanto os índices primários, mas são importantes também. Eles não são ordenados igual aos índices primários, por isso não são tão eficientes. Segue abaixo o diagrama de um índice secundário:

Como podemos ver, a folha de um índice secundário não contém o endereço físico dos dados indexados por ele, mas sim os endereços lógicos de um índice primário ou heap (entenda Heap como o local onde ficam armazenados os endereços físicos de uma tabela sem índice primário).
Continua...
Nenhum comentário:
Postar um comentário